While launching a bottoms-up SaaS product, Stratejos, from Terem, we saw users grow quickly month on month from a few hundred to over 15,000 active users per month. In the beginning we were able to click through each user account and get a sense of how they were using the product or getting stuck. Now, with this level of activity an early-stage SaaS product (or any digital product really) needs a more advanced analytics stack so we’ve developed one. We’re calling it the “Slightly Past MVP Bottoms-up SaaS Product Analytics Stack.”
This post will take you through what stack we’ve evolved to and how we got it setup.
I can’t advocate strongly enough for putting the time into an analytics stack. I say this out of experience. I’ve launched products without great analytics in place up-front which meant that we didn’t really understand what people were doing and so we made lots of poor decisions. With your analytics in place you will be able to build a much better product for your users and customers; you can release features and directly measure their success plus you can get the fine grained metrics you need to measure leading indicators of success.
Practical Tip: Keep in mind the Stack is focused on bottoms-up SaaS and might not be applicable to Enterprise SaaS Products or Consumer Products.
The Bottoms-up SaaS Product Analytics Stack
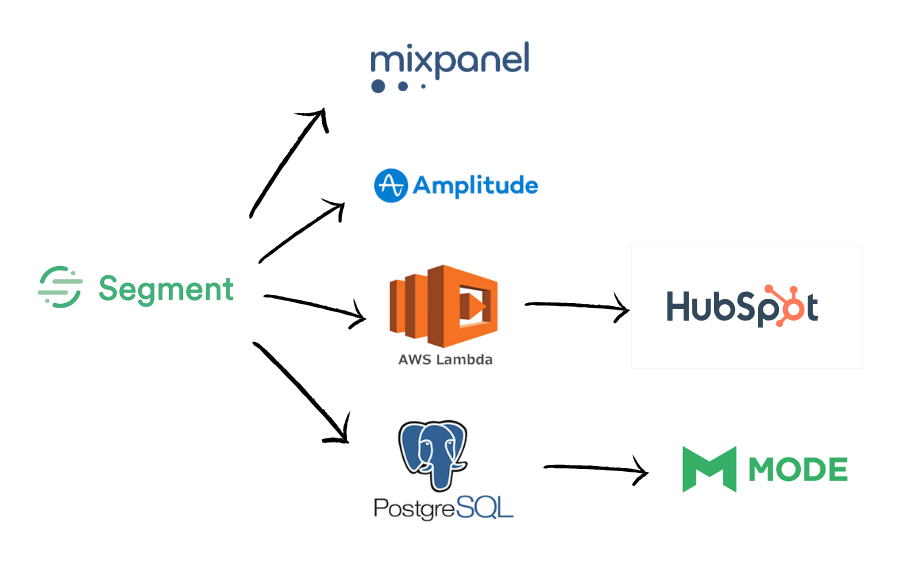
The Bottoms-up SaaS Product Analytics Stack we’re using is:
- Segment – so we can easily pipe analytics events where ever we want without troubling our engineers.
- Mixpanel – for a platform to understand usage.
- HubSpot – in an analytics context HubSpot is helping us visualise customer success.
- AWS Lambda with Custom Code – converts analytics events into companies in HubSpot so we can track customer success.
- Postgres – our Data Warehouse so we can run custom queries that cut across our application’s data, marketing tools as well as analytics events from Segment.
- Mode Analytics – to run ad-hoc queries across all of our data.
- Amplitude – we’re trying out Amplitude as an alternative to Mixpanel as we aren’t happy with Mixpanel’s ability to give analytics on by each company/team using the product.
How to set up the Stack
The main steps in setting up the Stack are:
- Setup Segment
- Connect your analytics tool of choice (for us this is Mixpanel / Amplitude)
- Connect HubSpot with Lambdas
- Setup Mode Analytics and a Data Warehouse for Ad-hoc Analysis
Setup Segment
The first step for the whole stack to work is to get Segment setup.
Segment does a great job of guiding you through doing this so just go and signup to Segment and use their documentation.
Connect analytics tools (Mixpanel, Amplitude)
Now you can get your analytics tools setup. To do this:
- Sign up to Mixpanel and/or Amplitude
- Connect it via Segment
Quick note here – you might want to go for the free tier and lean that way but life has taught me again and again that spending a few hundred dollars per month on a tool that gives you what you need is almost always a better investment.
Connect HubSpot with Lambdas
We wanted a view of how our customers were progressing at a high level through our product. This then means we could jump in and help as well as get an understanding of where people were getting stuck so we could fix things. It also gave us a view of an account for working out how to progress their success. Here is what our automated pipeline looks like in HubSpot:

The steps you can take to get to this are:
- Get a HubSpot account
- Code some Lambdas to take data from Segment and send it to HubSpot
Coding AWS Lambdas
This requires some explanation.
Firstly, I tried to do this without engineers using Zapier. But Zapier just couldn’t do the queries that we needed and the logic we needed. There were also some gaps in the data from our analytics events (e.g. some events contained the ID of the account/company the event was related to where as others didn’t). which meant that we needed to query the database sometimes to augment our data.
So the best next option was Lambdas. We wrote a few scripts in NodeJS and deployed them. It took some iteration to get the logic right but we got there in the end.
You don’t need to be wedded to Lambdas for this. You could equally write a Heroku app or similar. Whatever is easiest.
Setup Mode Analytics and a Data Warehouse for Ad-Hoc Analysis
Setting up Mode meant we could dig into the data from any angle we wanted to.
To start with there were some gaps in the data in our events that meant we couldn’t really understand the growth in users per account over time. So, this was the first query I wanted us to be able to run. We ran it in Mode Analytics, then exported to Excel for further charting.

Mode Analytics then lets the product team run all types of queries. Here is a query a Product Manager built for a specific new feature they launched:

In order to run this query we:
- Create a poor man’s Data Warehouse
- Create a read-replica database of production (if you don’t have it)
- Create a database for Segment to write analytics events to (see https://segment.com/docs/destinations/postgres/)
- Connect Segment to the Data Warehouse
- Sign up to Mode Analytics and Connect it to your Data Warehouse
Pro tip: You probably want to move to Redshift sooner rather than later. We went with postgres for cost reasons and because we just weren’t processing enough events yet to warrant Redshift.
Why a “poor man’s” Data Warehouse with multiple databases instead of just one database?
Instead of the “poor man’s” Data Warehouse I thought about calling this the “Data Warehouse Setup for the CEO That Used To Be a Programmer But Has Lost The Patience And Knowledge For Resolving Technical Challenges” then didn’t because although it was more amusing it was a bit too long.
I wanted to have the production read-replica and segment events in the same database. Naively I tried this first but it doesn’t work. I turned to our DevOps Engineer and asked what I was doing wrong and he pointed out that you can’t do this with a read-replica. So I ended up going ahead with the two as separate databases.
To have merged them into one I would have needed to setup a data pipeline that sends data from the read-replica to the single data warehouse. Going this extra step would have complicated this exercise further and not allowed me to gain too much more in terms of analytics capability at this stage. You may decide to go further.
Setting up the read-replica of production
I went to the Amazon Web Services console, then RDS => Instances. I then clicked on our production database and found the “create read replica” link to click. This setup my read-replica while I went and got lunch.
After it was set up I had some issues connecting Mode to it. As it was a read-replica you couldn’t connect to it on the usual port for Postgres. Which meant adding some extra Amazon security permissions and ensuring I entered the correct port in Mode as well as pgAdmin (I was using pgAdmin to test connections to databases).
Setting up the Segment Events Database
There were a few minor challenges getting the segment events database setup primarily around permissions in Postgres.
First, I used the instructions on https://segment.com/docs/destinations/postgres/.
I then ran into SQL permission issues that required our engineers to resolve. I’ll share about the problem in the hopes it helps you. The problem stemmed from creating a user for Segment to add data to the database and a separate user for Mode that could only read data from certain tables. I couldn’t get the user I had created for Mode to connect and run queries, then if I managed to get this working I broke the data flowing from the Segment user. This is important for security reasons so you limit your blast radius if you have any security issues with one of the services.

Scott Middleton
CEO & Founder
Scott has been involved in the launch and growth of 61+ products and has published over 120 articles and videos that have been viewed over 120,000 times. Terem’s product development and strategy arm, builds and takes clients tech products to market, while the joint venture arm focuses on building tech spinouts in partnership with market leaders.
Twitter: @scottmiddleton
LinkedIn: linkedin.com/in/scottmiddleton